
The program
In an AI-focused universe, we offer high-level scientific training that innovates to meet societal challenges and focuses on new economic, environmental, medical, industrial and financial issues.
Our MSc in AI Applied to Society is certified and registered in the Répertoire national des certifications professionnelles by CentraleSupélec and the French Ministry of Higher Education and Research (level 7 qualification). Find out more
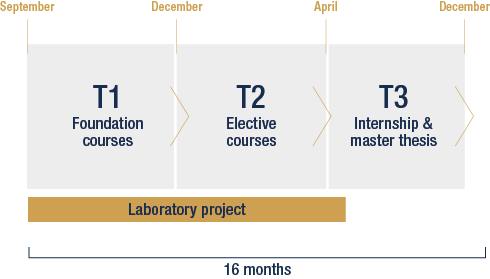
Program calendar

We are pleased to be able to welcome international students to a rich educational program and a stimulating environment in which they can flourish and progress. Artificial Intelligence (AI) is a science and a set of computational technologies that aim to solve complex problems involving some kinds of intelligence. The field of Artificial Intelligence is relatively young (1956) but spectacular advances have already been made, with significant impacts on society, and more to come. If you want to participate in the construction of the future enriched by responsible AI, nothing could be easier, just join our program.
Program
Foundation Courses
Machine learning is the scientific field that provides computers the ability to learn without being explicitly programmed. Machine learning lies at the heart of many real-world applications, including recommender systems, web search, computer vision, autonomous cars, and automatic language translation.
The course will provide an overview of fundamental topics as well as important trends in machine learning, including algorithms for supervised and unsupervised learning, dimensionality reduction
methods, and their applications. A substantial lab section will involve group projects on a data science competition and will provide the students with the ability to apply the course theory to real-world problems.
Optimization is the body of mathematical techniques at the root of all modern machine learning methods. Although these methods are quite varied, they can all be formulated as the minimization of a cost function over a given domain and under a set of constraints. Nonetheless, formulating a minimization problem is only a starting point. Indeed, many existing optimization methods depend on the structure of the problem at hand, some more efficient than others. This course aims to provide a comprehensive overview of classical optimization approaches and algorithms, both discrete and continuous. Participants will learn to practically address the various optimization problems they might encounter and choose an adequate algorithm.
The lecture will cover local and global optimization methods. The topics will include discrete, derivative-free optimization, gradient, and second-order based algorithms, constrained optimization, duality, non-smooth methods, and an introduction to stochastic and global algorithms. The course will use machine-learning methods as illustrations but occasionally draw on other examples.
Big data is a generic term that indicates large datasets that are so large and complex that traditional data-processing methods are unable to deal with them. These are typically impossible to store on any single computer no matter how powerful. As examples, think of the collection of web pages of the whole Internet ; all the medical exams of the entire healthcare system in France or the USA ; or the collision data from the Large Hadron Collider in Geneva. Somewhat smaller datasets are daunting too: the catalog of auto parts for all cars on the road today, for example, or the collection of photos on Facebook (estimated at 50 billions). One estimates that the entire Internet traffic is in the order of one zettabyte per year (1021 bytes) and doubling every year.
In this course, we will introduce start-of-art techniques of distributed data processing, which a particular focus on Apache Spark and its high-level libraries for handling (semi-)structured data, streaming data and graph data.
We’ll also cover the MLlib library that Spark provides to train, test and deploy machine learning models at scale.
Deep Learning becomes more and more popular with algorithms based on these techniques performing very well for a variety of problems and scientific communities. The course has been designed
to provide an introduction to deep learning techniques, including neural networks, computer vision, natural image processing. In particular, it will cover the fundamental aspects and the recent
developments in deep learning: Feedforward networks and their optimization and regularization, representation learning and siamese networks, Generative Adversarial Networks and transfer learning, recurrent networks and Long Short Term Memory units.
Artificial Intelligence is experiencing another hype phase with huge funding from private companies and States. The history of this fascinating scientific field shows it is not the first hype phase, and probably not the last one. The course is an opportunity to familiarize with the history of IA, its founding fathers and the actual great names in this field.
It is an overview of the different approaches of Artificial Intelligence: from reflex agent (low level AI) to expert systems and xIA (high level AI) and will show different categories of problems AI can solve. Each approach will be illustrated with real world applications.
The course will provide an overview of fundamental topics as well as important trends in machine learning, including algorithms for supervised and unsupervised learning, dimensionality reduction methods and their applications. A substantial lab section will involve group projects on a data science competition and will provide the students the ability to apply the course theory to real-world problems.
Preferences are present and pervasive in many situations involving human interaction and decisions.
Preferences are expressed explicitly or implicitly in numerous applications, and relevant decisions should be made based on these preferences. This course aims at introducing preference models for multicriteria decisions. We will present concepts and methods for preference modeling and multicriteria decision-making.
In these two sessions, we will tackle a key question – what can possibly go wrong when implementing new technologies, and AI in particular? Building on numerous examples taken from the peerreviewed literature, we will explore aspects that need attention when developing, calibrating, testing, and deploying AI-based tools.
The first lecture will introduce ethical issues: biases, responsibility, privacy, and sustainability. Based on a human factors/ergonomics perspective, the second lecture will show how failure to think about AI as one element of a larger system can lead to unexpected consequences.
Elective Courses
This course will give an overview of the topics of study of the field of Natural Language Processing.
It will take a problem-centric approach, introducing increasingly complex problems, starting from basic building blocks like language modeling, tagging and parsing; and progressing towards complex problems like opinion mining, machine translation, question & answering and dialogue. While important historical methods will be mentioned (and studied if still relevant), a focus will be on current state-of-the-art involving many times recent advances in training neural networks and novel architectures.
Computer vision is an interdisciplinary field with the goal of enabling automatical processing and understanding of digital images. These images can be captured by video cameras, radars, satellites
or even very specialised sensors such as the ones used for medical purposes. This course covers both theoretical and practical aspects of computer vision. It has been designed to provide an introduction to computer vision, including fundamentals on image processing, computational photography, multiview geometry, stereo, tracking, segmentation and object detection. It will expose students to a number of real-world applications that are important to our daily life. The course will be focusing only on classical computer vision techniques, presenting a detailed overview of classical vision methods, while it does not cover deep learning-based methods.
Reinforcement Learning (RL) methods are at the intersection of several fields such as machine learning, probability theory, control theory, or game theory. They study fundamental tradeoffs between exploitation and exploration in order to optimize a future reward in an unknown environment. Recently, they were successfully applied to many applications such as complex games (Go or Atari), robot control, and selection of experts, leading in many cases to super-human performances in those contexts. This class will cover the necessary tools (from a theoretical and practical point of view) to understand how such a breakthrough was possible.
Deep learning methods are now state of the art in many machine learning tasks, leading to impressive results. Nevertheless, they are still poorly understood, neural networks are still difficult to train,
and the results are black-boxes missing explanations. Given the societal impact of machine learning techniques today (used as assistance in medicine, hiring process, and bank loans…), it is crucial to make their decisions explainable or to offer guarantees. Besides, real world problems usually do not fit the standard assumptions or frameworks of the most famous academic work (data quantity and quality, expert knowledge availability…). This course aims at providing insights and tools to address these practical aspects, based on mathematical concepts.
Networks (or graphs) have become ubiquitous as data from diverse disciplines can naturally be mapped to graph structures. Social networks, such as academic collaboration networks and interaction networks over online social networking applications are used to represent and model social ties among individuals. Information networks, including the hyperlink structure of the Web and blog networks, have become crucial mediums for information dissemination, offering an effective way to represent content and navigate through it. A plethora of technological networks, including the Internet, power grids, telephone networks and road networks are an important part of everyday life. The problem of extracting meaningful information from large-scale graph data in an efficient and effective way has become crucial and challenging with several important applications. Towards this end, graph mining and analysis methods constitute prominent tools. The goal of this course is to present
recent and state-of-the-art methods and algorithms for analyzing, mining and learning large-scale graph data, as well as their practical applications in various domains (e.g., the web, social networks,
recommender systems).
Medical imaging technologies provide unparalleled means to study the structure and function of the human body in vivo. Interpretation of medical images is difficult due to the need to take into account three-dimensional, time-varying information from multiple types of medical images. Artificial intelligence (AI) holds great promise for assisting in the interpretation and medical imaging is one of the areas where AI is expected to lead to the most important successes. In the past years, deep learning technologies have led to impressive advances in medical image processing and interpretation.
This course covers both theoretical and practical aspects of deep learning for medical imaging. It covers the main tasks involved in medical image analysis (classification, segmentation, registration,
generative models…) for which state-of-the-art deep learning techniques are presented, alongside some more traditional image processing and machine learning approaches. Examples of different
types of medical imaging applications (brain, cardiac…) will also be provided.
The ensemble methods are popular machine learning techniques that are powerful when one wants to deal with both classification and regression prediction problems. The idea is to build a global prediction model by combining the strengths of a set of simpler base models. The random Forests approach is an example that falls into this category by the aggregation of a collection of decision trees.
This course aims to study the fundamental notions and concepts of tree-based methods and ensemble learning. Mainly, we will introduce several methods, such as Classification And Regression Trees (CART), boosting trees, Random Forests, …etc. Furthermore, we want to investigate and discuss some recent challenges of interpretability and regularization through different approaches [Strobl et al., 2007, 2008]. Moreover, the different approaches will be applied to practical cases involving real data throughout the course.
Multi-agent systems (MAS) are currently widely used, especially for complex applications requiring interaction between several entities. More specifically, they are used in applications where it is necessary to solve problems in a distributed manner (data processing) or in the design of distributed systems in which each component has some degree of autonomy (control of processes). Some examples of applications are trading agents, drones, smart grids. This course will begin with an introduction to the notion of agent and multi-agent systems. It will present the concepts that will lead to an understanding of what an agent is and how it can be built. Then, we will address a classical problem of SMAs, namely, how to model and simulate a situation through the concept of agents.
The idea is to give a basis for understanding how agent-based simulations can be used as a tool for understanding human societies or complex problems and situations. Besides, we will discuss how agents can communicate and interact to solve problems, and more specifically, to make noncentralized decisions. For this, we will rely on negotiation protocols based on argumentation theory, a process of constructing and evaluating arguments (positive and negative reasons/evidence) to resolve conflicts.
Maintenance is important in engineering systems. In this course, we focus on the optimal planning of maintenance for complex systems. Different maintenance strategies are introduced with a focus on the performance indicators used to quantify their performances and optimization models used to obtain optimal planning. The students are supposed to learn fundamental theoretical results as well as some tools to help them apply the theoretical methods in practical.
Planning in AI focuses on automatically generating sequences of actions that must be performed in order to reach a predefined goal. Actions are represented by operators transforming the states, generally expressed via propositional logic. Several problems in industry or robotics can be formulated as planning problems. Different AI techniques and algorithms are used to solve planning problems.
In classical planning, an agent has perfect knowledge of the states and the effects of the actions, which are deterministic. The relaxation of these assumptions leads to numerous extensions using solving techniques based on diverse AI tools like heuristic search or Markov processes.
In this course, we will introduce the formulation of a planning problem and present the different AI techniques and algorithms for solving it,
Artificial Intelligence aims to solve problems automatically. In particular, Deep Learning allows reaching performances that are often greater than human performances. However, in some application areas, users want to understand why an algorithm proposes a certain decision. This is especially true for human-centered domains, such as medicine and security, or for those that are affected by laws offering a right to explanation (banking sector). For these reasons, the field of XAI (eXplainable Artificial Intelligence) has become very important in recent years, even though the issue has been around for several decades.
This module aims to introduce you to the tools that have emerged from recent or older research and that help to understand the most opaque models, and to familiarize you with interpretability and explainability issues. At the end of this course, the student will have acquired a general view of the XIA domain and its problems.
Decision-making is an indispensable task in engineering practices. In this course, we focus on the basic concepts, principles, and decision-making techniques using optimization models, especially in the presence of uncertainties.
The students are supposed to learn how to model optimization problems that involve risk and uncertainty with the help of analytical models and off-the-shelf software. The course covers analytical models such as the basics of Convex Optimization, Stochastic Programming, Risk Control in Stochastic Optimization, Two-stage Stochastic Programming, Decomposition algorithms, Markov Decision Process, Dynamic Programming, etc. The course is hands-on. The emphasis will be on model formulation, practical problem solving and implementation, as well as interpretation of results.
AI cannot be applied in a straightforward way to finance for three essential reasons: data are extremely noisy, their distribution is usually far more dangerous than a Gaussian one, and everything is nonstationary. These basic facts of life in finance require therefore special care, that is, specific methodologies and expertise.
This course aims at giving a practical approach to applying AI to finance: starting from fundamental concepts and objects it then explores price formation in high-frequency data in limit order books, introduces modern methods of portfolio optimization, explains the good practices of trading strategy performance backtesting, and finally reviews what kind of DL/ML/RL approaches work in finance.

Lab project
(October to March)
Students, working in pairs, select a research topic tutored by a faculty member in an associated laboratory. The topic corresponds to a state-of-the-art problem. Students are asked to assess the existing literature, propose an algorithmic solution to the problem at hand, implement it, and provide numerical validation.

Internship & Master Thesis
To complete the CentraleSupélec MSc in Artificial Intelligence, students must acquire professional experience (by means of a 4-6 month internship or a job in a position related to the program) and complete the related Master’s Thesis. This corresponds to a natural extension of the course work carried out during the academic year.

“For my internship, I joined Kayrros where we provide clients with climate data to reduce greenhouse gas emissions, and manage the energy transition. We leverage advanced algorithms, satellite imagery and other data to empower global climate governance. I am part of the WildFire team working on wildfire prevention, optimizing risk profiling and automate damage assessment. The MSc AI gave me a solid base in Machine Learning, data analysis and Deep Learning which has served me well in my work.”


“Data-driven approaches for predictive maintenance planning is a hot AI application topic. I am coaching a lab project in the MSc AI on predictive maintenance planning by fusing physics-based and deep learning models. Monitoring signals of degradation processes are used to predict the remaining useful life of the system, and preventive maintenance decisions are made based on the predicted remaining useful life.”


“During my MSc AI internship, I’ve been working as a computer vision engineer for LIXO a green tech start-up that analyses in real time the composition of the waste streams collected. I’ve been tasked to implement advanced data augmentation techniques along with an instance segmentation pipeline in order to improve the efficiency of their current solution. I’ve found that the internship is a vital part of the Msc AI’s curriculum seeing as there is so much practical knowledge to be acquired from a corporate setting.”


HEALTH AND MEDECINE
“The Master of Science in AI prepared me for my first research experience with an internship at the Paris Brain Institute (ICM) for automatic segmentation of brain MRI images. This first research experience convinced me to continue on with a PhD in the field. So I started a PhD between CentraleSupélec and the ICM with application to multiple sclerosis diagnosis, which combines advances in AI methods and actual impact on the application level.”

Application informations
Who can apply ?
- Recent graduates or soon-to-be graduates that have validated at least 4 year higher education - 240 ECTS (4 year bachelor/Master 1,...) Engineering, Mathematics, Statistics, Informatics, Physics …
- With little to no work experience
-
A good level of English, and looking to study entirely in English
The expected level is C1, with minimum results as:- IELTS (6.5)
- TOEFL iBT (110)
- Cambridge English Advanced (180)
- TOEIC (945)
The English test is not required if the candidate is a native English speaker or has spent the last 3 years in a 100% English-speaking University. - And aiming to become an expert and leader in AI.
Financing
Tuition fees: €20,000 including €2,000 deposit. The deposit is payable upon acceptance into the program and before registration. This amount is later deducted from your tuition fees. Remaining tuition fees can be paid in one, two, or three installments before December.
Any questions ?
Admissions
Online application deadlines :
- Round 1 : Nov 28th, 2025
- Round 2 : Jan 26th, 2026
- Round 3 : March 16th, 2026
- Round 4 : May 11th, 2026
- Round 5 : June 22nd, 2026
- Round 6 : July 9th, 2026